Tutorial-1: Continual Integration of Mosaic Single-cell Data (RNA+ADT+ATAC)#
Objective:
In this tutorial, we demonstrate how to perform continual integration on a mosaic single-cell dataset spanning eight batches with diverse modality combinations.
Workflow:
Preparation: Set up the environment and download the mosaic dataset.
Base Training: Train an initial model on the first batch (Batch 1).
Continual Integration: Incrementally update the model with incoming data (Batches 2-8) without accessing previous raw data.
(optional) Packaging: Merge datasets.
Step 1: Initialization and Environment Setup#
We start by importing necessary libraries, defining global configurations, and setting a random seed to ensure reproducibility.
[1]:
import warnings
warnings.filterwarnings('ignore')
import os
import lightning as L
import numpy as np
import pandas as pd
import scanpy as sc
# Import custom modules from the scmiracle library
from scmiracle.config import load_config
from scmiracle.data import download_data
from scmiracle.model import MIDAS
from scmiracle.plot import plot_umap
from scmiracle.utils import calculate_loss_scale
# --- Global Configurations ---
# Use os.path.join for cross-platform path compatibility
BASE_DATA_PATH = './'
DATASET_NAME = 'DOTEA_mtx'
DATA_PATH = os.path.join(BASE_DATA_PATH, 'dataset', DATASET_NAME)
SAVE_MODEL_DIR = './'
# --- GPU Configuration ---
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# --- Scanpy Plotting Parameters ---
sc.set_figure_params(figsize=(4, 4))
# --- Global Random Seed ---
# Set a global random seed for reproducibility
L.seed_everything(42)
# --- Dataset and Model Parameters ---
# Number of cells per batch, used for calculating loss weights
NUM_CELLS_PER_BATCH = np.array([9579, 9096, 7318, 4817, 5342, 6181, 4163, 6860])
# Number of workers for data loading; adjust based on your CPU core count
NUM_WORKERS = 64
# Training epochs: 2000 for the base model, 1000 for each incremental step
NUM_EPOCH = [2000] + [1000] * 7
Seed set to 42
Step 2: Data Preparation#
We download the demonstration dataset.
Note on Data Structure: This dataset is pre-processed to simulate an online learning scenario.
RNA & ADT: Features in new batches are aligned with existing features (Reference features first, New features last).
ATAC: Features are consistent across all batches.
[ ]:
# Download the dataset
download_data(DATASET_NAME, BASE_DATA_PATH)
# Load Ground Truth labels for evaluation
labels = [pd.read_csv(os.path.join(DATA_PATH, f'label/P{i+1}_l1.csv'), index_col=0).values.flatten() for i in range(8)]
Step 3: Base Model Training (Batch 1)#
We follow the standard MIDAS procedure to build a robust initial model using only the first batch. This establishes the “base knowledge.”
[3]:
print("\n--- Stage 1: Training the base model on Batch 1 ---")
# Reset the MIDAS model state for a clean start
MIDAS.reset()
configs = load_config()
configs['num_workers'] = NUM_WORKERS
# Configure the data and model from the first batch directory
model = MIDAS.configure_data_from_dir(
configs=configs,
dir_path=os.path.join(DATA_PATH, 'data','DOTEA_P1'),
save_model_path=os.path.join(SAVE_MODEL_DIR, 'DOTAE_P1'),
format='mtx',
transform={'atac': 'binarize'} # Binarize ATAC data
)
# Initialize and fit with a Lightning Trainer (approx. 100 mins for 2000 epochs)
trainer = L.Trainer(max_epochs=NUM_EPOCH[0])
trainer.fit(model=model)
# model.load_checkpoint(os.path.join(SAVE_MODEL_DIR, 'saved_models', 'DOTAE_P1_mtx', 'model.pt'))
# Generate predictions and visualize the latent space
pred = model.predict(return_format='anndata')['DOTEA_P1']
pred.obs['label'] = labels[0]
plot_umap(pred, color=['batch', 'label'], wspace=0.4)
INFO:root:The model is initialized with the default configurations.
--- Stage 1: Training the base model on Batch 1 ---
INFO:root:Input data:
#CELL #ADT #ATAC #VALID_ADT
DOTEA_P1 9579 208 31787 208
INFO:root:Defining new network structure...
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 10.5 M | train
1 | dsc | Discriminator | 38.8 K | train
-----------------------------------------------
10.6 M Trainable params
0 Non-trainable params
10.6 M Total params
42.258 Total estimated model params size (MB)
640 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 9579 from 1 datasets.
INFO:root:Using MultiBatchSampler for data loading.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P1/model_epoch500_20260411-022103.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P1/model_epoch1000_20260411-030236.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P1/model_epoch1500_20260411-034423.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P1/model_epoch2000_20260411-042617.pt".
`Trainer.fit` stopped: `max_epochs=2000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P1/model_epoch2000_20260411-042618.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:03<00:00, 11.94it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
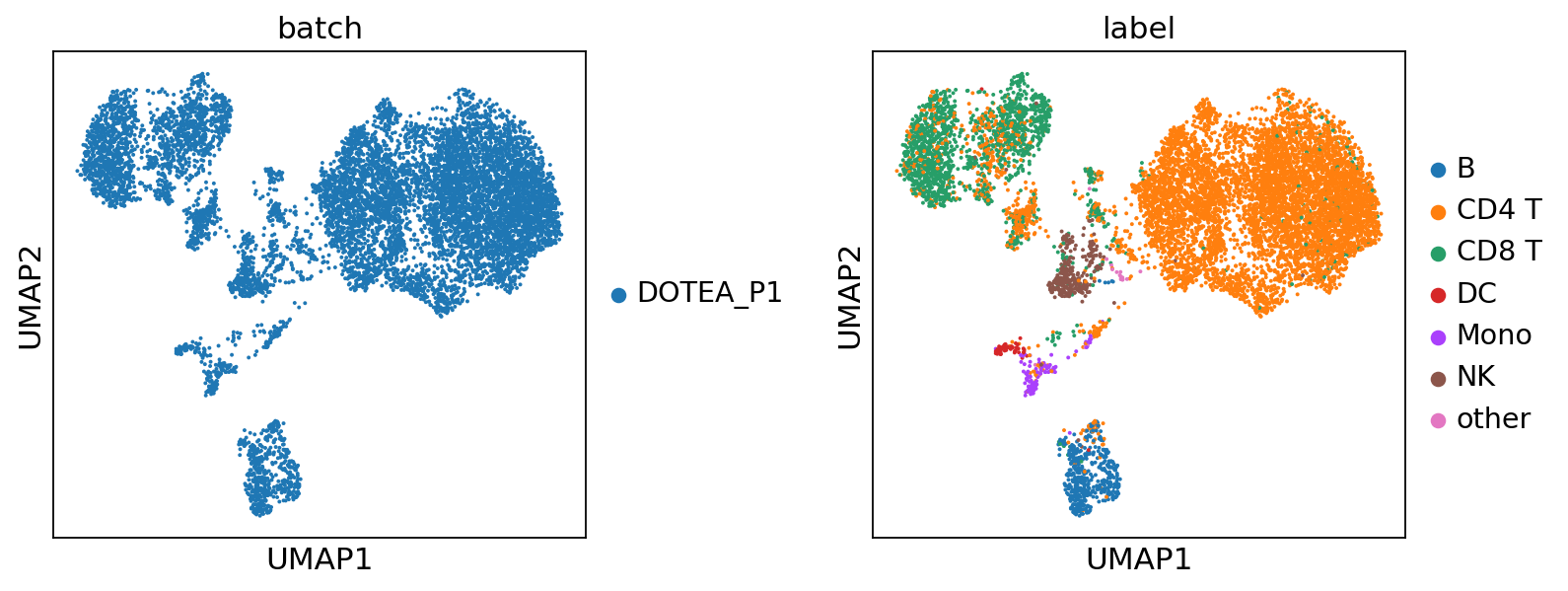
Step 4: Continual Integration (Batches 2–8)#
In this stage, we simulate a stream of incoming data. We update the model incrementally with Batches 2 to 8.
Key Concept: calculate_loss_scale is used to balance the model’s plasticity (learning new data) and stability (remembering old data).
[4]:
print("\n--- Stage 2: Continual Training on Batches 2-8 ---")
for step in range(1, 8):
print(f"\n--- Processing Batch {step + 1} ---")
# 1. Calculate Loss Scaling
# Balances the weight of the previous model (old knowledge) vs. current batch (new knowledge)
scale = calculate_loss_scale(NUM_CELLS_PER_BATCH[:step], NUM_CELLS_PER_BATCH[[step]])
# 2. Configure continual integration model
# Note: We use 'configure_new_data_from_dir' to extend the existing model
miracle = MIDAS.configure_new_data_from_dir(
configs=configs,
dir_path=os.path.join(DATA_PATH, 'data', f'DOTEA_P{step+1}'),
save_model_path=os.path.join(SAVE_MODEL_DIR, f'DOTAE_P{step+1}'),
format='mtx',
transform={'atac': 'binarize'},
scale=scale
)
# 3. Update the Model
trainer = L.Trainer(max_epochs=NUM_EPOCH[step])
trainer.fit(model=miracle)
# model.load_checkpoint(os.path.join(SAVE_MODEL_DIR, 'saved_models', f'DOTAE_P{step+1}', 'model.pt'))
# 4. Visualization
# Concatenate predictions from all batches processed so far to check integration
pred = sc.concat(miracle.predict(return_format='anndata'))
pred.obs['label'] = np.concatenate(labels[:step+1])
plot_umap(pred, color=['batch', 'label'], wspace=0.4)
--- Stage 2: Continual Training on Batches 2-8 ---
--- Processing Batch 2 ---
INFO:root:Input data:
#CELL #ADT #ATAC #RNA #VALID_ADT #VALID_RNA
DOTEA_P1 9579 208.0 31787 NaN 208.0 NaN
DOTEA_P2 9096 NaN 31787 4052.0 NaN 4052.0
INFO:root:Loading pre-defined network structure...
INFO:root:Model1 updated successfully with weights from model2 (left-aligned strategy).
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 18.8 M | train
1 | dsc | Discriminator | 51.8 K | train
-----------------------------------------------
18.9 M Trainable params
0 Non-trainable params
18.9 M Total params
75.533 Total estimated model params size (MB)
666 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 18675 from 2 datasets.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P2/model_epoch500_20260411-054838.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P2/model_epoch1000_20260411-071043.pt".
`Trainer.fit` stopped: `max_epochs=1000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P2/model_epoch1000_20260411-071043.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:04<00:00, 9.29it/s]
INFO:root:Processing batch DOTEA_P2: ['atac', 'rna']
100%|██████████| 36/36 [00:04<00:00, 8.46it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
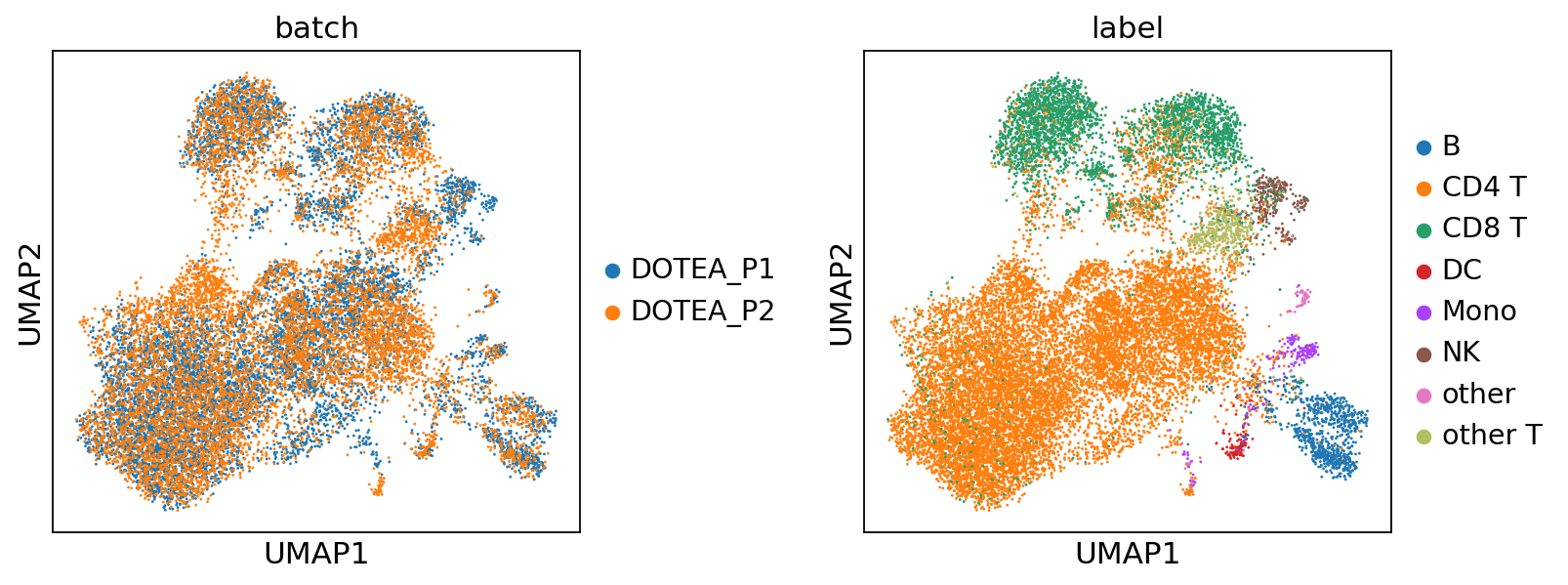
--- Processing Batch 3 ---
INFO:root:Input data:
#CELL #ADT #ATAC #RNA #VALID_ADT #VALID_RNA
DOTEA_P1 9579 208.0 31787.0 NaN 208.0 NaN
DOTEA_P2 9096 NaN 31787.0 4959.0 NaN 4052.0
DOTEA_P3 7318 208.0 NaN 4959.0 208.0 4063.0
INFO:root:Loading pre-defined network structure...
INFO:root:Model1 updated successfully with weights from model2 (left-aligned strategy).
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 20.7 M | train
1 | dsc | Discriminator | 52.0 K | train
-----------------------------------------------
20.7 M Trainable params
0 Non-trainable params
20.7 M Total params
82.968 Total estimated model params size (MB)
666 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 25993 from 3 datasets.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P3/model_epoch500_20260411-080938.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P3/model_epoch1000_20260411-090817.pt".
`Trainer.fit` stopped: `max_epochs=1000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P3/model_epoch1000_20260411-090818.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:04<00:00, 8.36it/s]
INFO:root:Processing batch DOTEA_P2: ['atac', 'rna']
100%|██████████| 36/36 [00:04<00:00, 7.73it/s]
INFO:root:Processing batch DOTEA_P3: ['adt', 'rna']
100%|██████████| 29/29 [00:03<00:00, 7.25it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
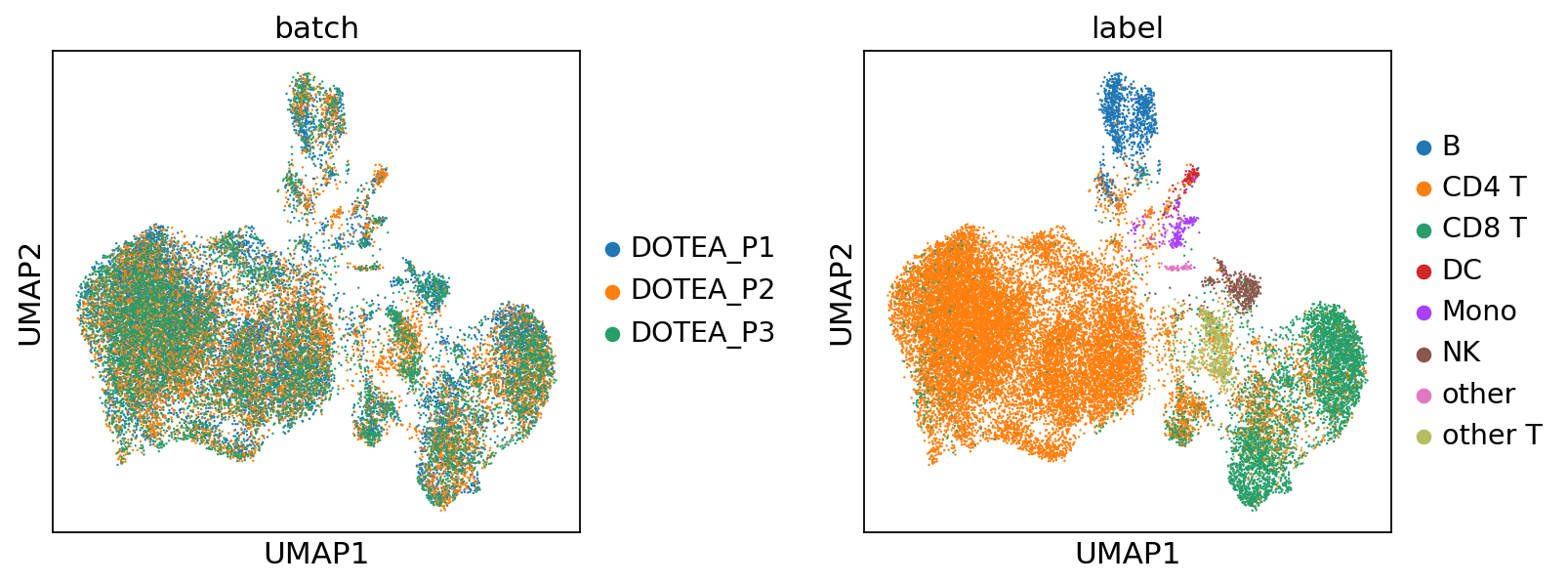
--- Processing Batch 4 ---
INFO:root:Input data:
#CELL #ADT #ATAC #RNA #VALID_ADT #VALID_RNA
DOTEA_P1 9579 208.0 31787.0 NaN 208.0 NaN
DOTEA_P2 9096 NaN 31787.0 5439.0 NaN 4052.0
DOTEA_P3 7318 208.0 NaN 5439.0 208.0 4063.0
DOTEA_P4 4817 208.0 31787.0 5439.0 208.0 4050.0
INFO:root:Loading pre-defined network structure...
INFO:root:Model1 updated successfully with weights from model2 (left-aligned strategy).
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 21.7 M | train
1 | dsc | Discriminator | 52.3 K | train
-----------------------------------------------
21.7 M Trainable params
0 Non-trainable params
21.7 M Total params
86.903 Total estimated model params size (MB)
666 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 30810 from 4 datasets.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P4/model_epoch500_20260411-095435.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P4/model_epoch1000_20260411-103852.pt".
`Trainer.fit` stopped: `max_epochs=1000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P4/model_epoch1000_20260411-103853.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:05<00:00, 7.60it/s]
INFO:root:Processing batch DOTEA_P2: ['atac', 'rna']
100%|██████████| 36/36 [00:04<00:00, 7.36it/s]
INFO:root:Processing batch DOTEA_P3: ['adt', 'rna']
100%|██████████| 29/29 [00:04<00:00, 6.78it/s]
INFO:root:Processing batch DOTEA_P4: ['adt', 'atac', 'rna']
100%|██████████| 19/19 [00:04<00:00, 4.16it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
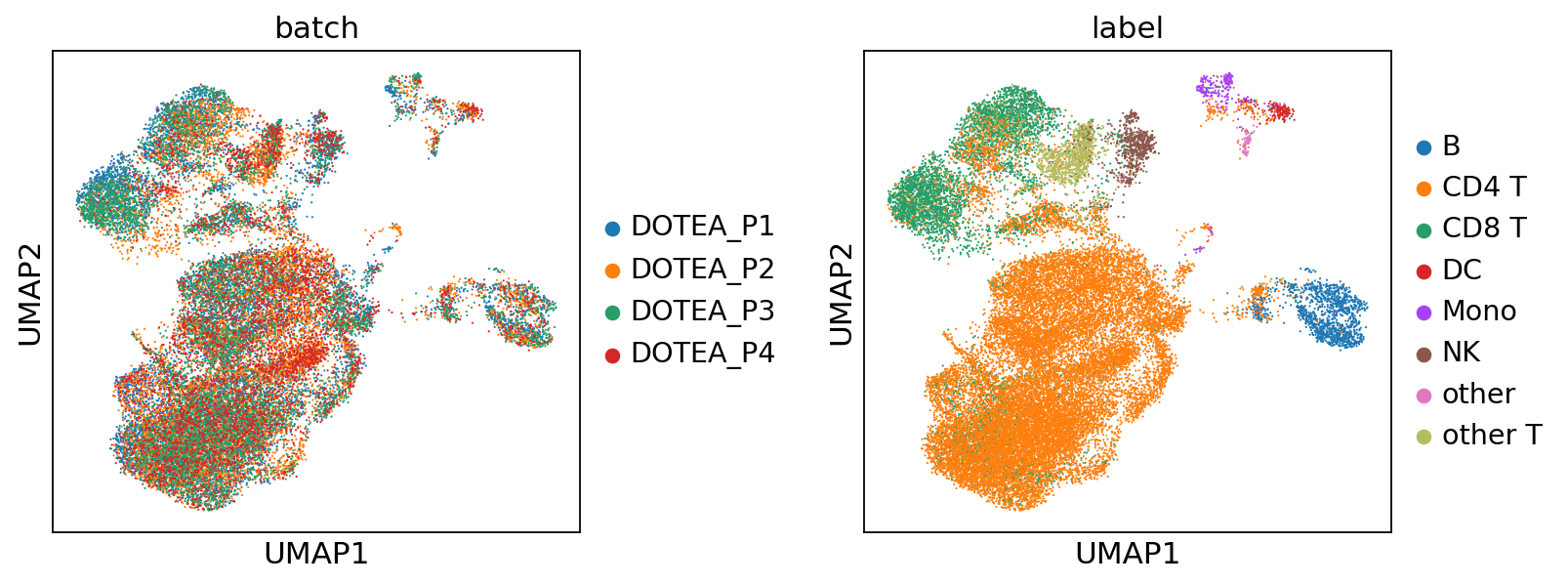
--- Processing Batch 5 ---
INFO:root:Input data:
#CELL #ADT #ATAC #RNA #VALID_ADT #VALID_RNA
DOTEA_P1 9579 213.0 31787.0 NaN 208.0 NaN
DOTEA_P2 9096 NaN 31787.0 5439.0 NaN 4052.0
DOTEA_P3 7318 213.0 NaN 5439.0 208.0 4063.0
DOTEA_P4 4817 213.0 31787.0 5439.0 208.0 4050.0
DOTEA_P5 5342 213.0 31787.0 NaN 45.0 NaN
INFO:root:Loading pre-defined network structure...
INFO:root:Model1 updated successfully with weights from model2 (left-aligned strategy).
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 21.7 M | train
1 | dsc | Discriminator | 52.5 K | train
-----------------------------------------------
21.7 M Trainable params
0 Non-trainable params
21.7 M Total params
86.945 Total estimated model params size (MB)
666 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 36152 from 5 datasets.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P5/model_epoch500_20260411-112513.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P5/model_epoch1000_20260411-121040.pt".
`Trainer.fit` stopped: `max_epochs=1000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P5/model_epoch1000_20260411-121041.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:04<00:00, 7.68it/s]
INFO:root:Processing batch DOTEA_P2: ['atac', 'rna']
100%|██████████| 36/36 [00:04<00:00, 7.29it/s]
INFO:root:Processing batch DOTEA_P3: ['adt', 'rna']
100%|██████████| 29/29 [00:04<00:00, 6.60it/s]
INFO:root:Processing batch DOTEA_P4: ['adt', 'atac', 'rna']
100%|██████████| 19/19 [00:04<00:00, 3.96it/s]
INFO:root:Processing batch DOTEA_P5: ['adt', 'atac']
100%|██████████| 21/21 [00:04<00:00, 4.53it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
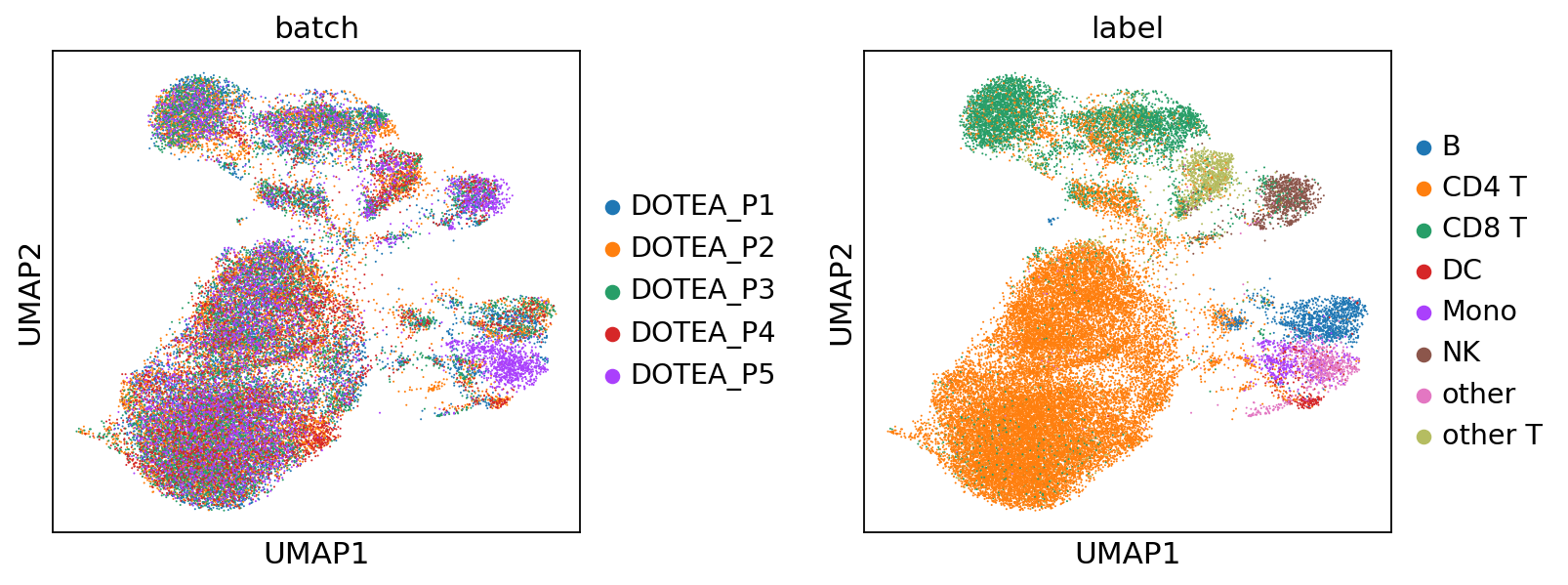
--- Processing Batch 6 ---
INFO:root:Input data:
#CELL #ADT #ATAC #RNA #VALID_ADT #VALID_RNA
DOTEA_P1 9579 213.0 31787.0 NaN 208.0 NaN
DOTEA_P2 9096 NaN 31787.0 6606.0 NaN 4052.0
DOTEA_P3 7318 213.0 NaN 6606.0 208.0 4063.0
DOTEA_P4 4817 213.0 31787.0 6606.0 208.0 4050.0
DOTEA_P5 5342 213.0 31787.0 NaN 45.0 NaN
DOTEA_P6 6181 NaN 31787.0 6606.0 NaN 4064.0
INFO:root:Loading pre-defined network structure...
INFO:root:Model1 updated successfully with weights from model2 (left-aligned strategy).
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 24.1 M | train
1 | dsc | Discriminator | 52.7 K | train
-----------------------------------------------
24.1 M Trainable params
0 Non-trainable params
24.1 M Total params
96.511 Total estimated model params size (MB)
666 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 42333 from 6 datasets.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P6/model_epoch500_20260411-130601.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P6/model_epoch1000_20260411-140002.pt".
`Trainer.fit` stopped: `max_epochs=1000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P6/model_epoch1000_20260411-140003.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:05<00:00, 6.85it/s]
INFO:root:Processing batch DOTEA_P2: ['atac', 'rna']
100%|██████████| 36/36 [00:05<00:00, 6.04it/s]
INFO:root:Processing batch DOTEA_P3: ['adt', 'rna']
100%|██████████| 29/29 [00:05<00:00, 5.68it/s]
INFO:root:Processing batch DOTEA_P4: ['adt', 'atac', 'rna']
100%|██████████| 19/19 [00:05<00:00, 3.62it/s]
INFO:root:Processing batch DOTEA_P5: ['adt', 'atac']
100%|██████████| 21/21 [00:05<00:00, 3.92it/s]
INFO:root:Processing batch DOTEA_P6: ['atac', 'rna']
100%|██████████| 25/25 [00:05<00:00, 4.67it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
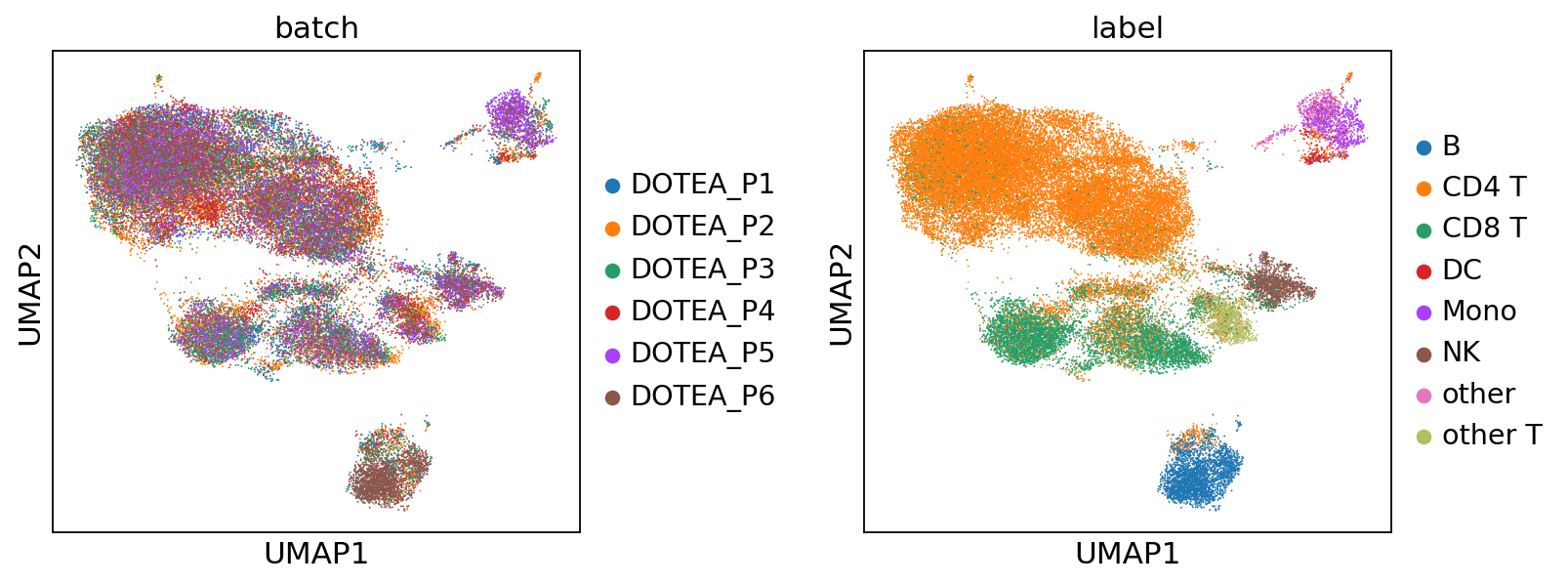
--- Processing Batch 7 ---
INFO:root:Input data:
#CELL #ADT #ATAC #RNA #VALID_ADT #VALID_RNA
DOTEA_P1 9579 213.0 31787.0 NaN 208.0 NaN
DOTEA_P2 9096 NaN 31787.0 7077.0 NaN 4052.0
DOTEA_P3 7318 213.0 NaN 7077.0 208.0 4063.0
DOTEA_P4 4817 213.0 31787.0 7077.0 208.0 4050.0
DOTEA_P5 5342 213.0 31787.0 NaN 45.0 NaN
DOTEA_P6 6181 NaN 31787.0 7077.0 NaN 4064.0
DOTEA_P7 4163 213.0 NaN 7077.0 45.0 4071.0
INFO:root:Loading pre-defined network structure...
INFO:root:Model1 updated successfully with weights from model2 (left-aligned strategy).
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 25.0 M | train
1 | dsc | Discriminator | 52.9 K | train
-----------------------------------------------
25.1 M Trainable params
0 Non-trainable params
25.1 M Total params
100.372 Total estimated model params size (MB)
666 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 46496 from 7 datasets.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P7/model_epoch500_20260411-143356.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P7/model_epoch1000_20260411-150627.pt".
`Trainer.fit` stopped: `max_epochs=1000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P7/model_epoch1000_20260411-150628.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:05<00:00, 6.73it/s]
INFO:root:Processing batch DOTEA_P2: ['atac', 'rna']
100%|██████████| 36/36 [00:05<00:00, 6.18it/s]
INFO:root:Processing batch DOTEA_P3: ['adt', 'rna']
100%|██████████| 29/29 [00:05<00:00, 5.41it/s]
INFO:root:Processing batch DOTEA_P4: ['adt', 'atac', 'rna']
100%|██████████| 19/19 [00:05<00:00, 3.56it/s]
INFO:root:Processing batch DOTEA_P5: ['adt', 'atac']
100%|██████████| 21/21 [00:05<00:00, 3.92it/s]
INFO:root:Processing batch DOTEA_P6: ['atac', 'rna']
100%|██████████| 25/25 [00:05<00:00, 4.42it/s]
INFO:root:Processing batch DOTEA_P7: ['adt', 'rna']
100%|██████████| 17/17 [00:04<00:00, 3.47it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
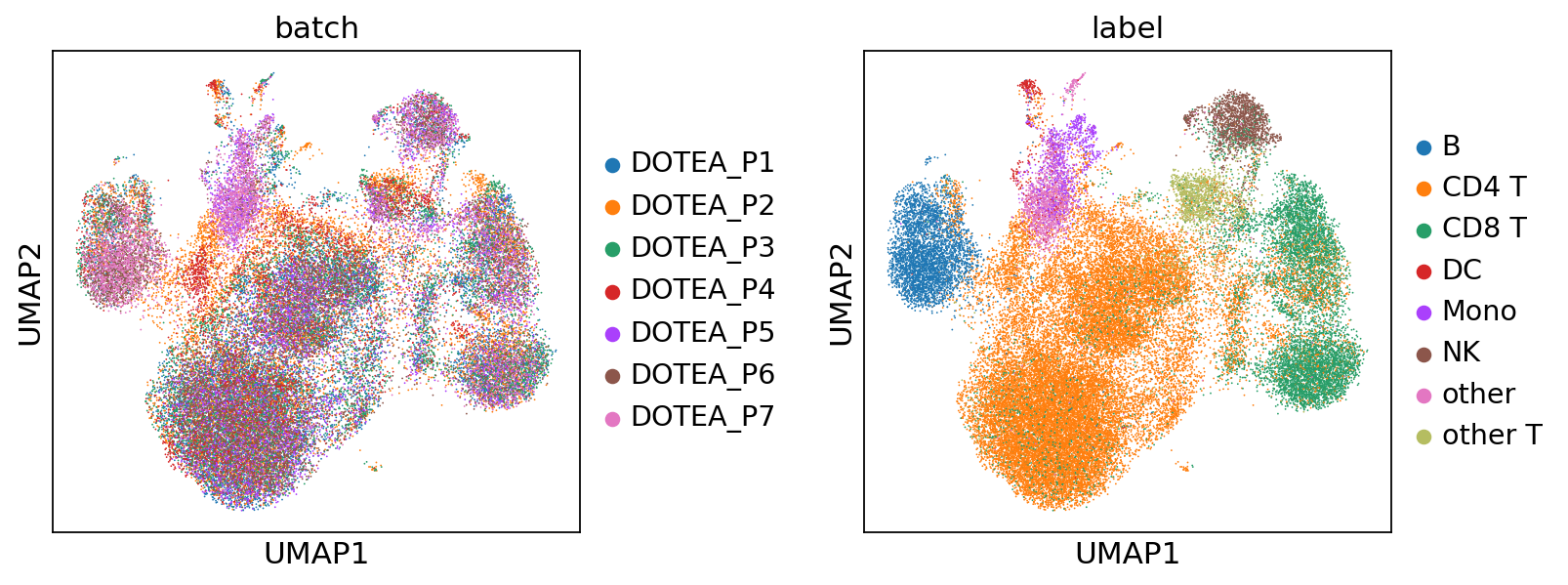
--- Processing Batch 8 ---
INFO:root:Input data:
#CELL #ADT #ATAC #RNA #VALID_ADT #VALID_RNA
DOTEA_P1 9579 213.0 31787.0 NaN 208.0 NaN
DOTEA_P2 9096 NaN 31787.0 7304.0 NaN 4052.0
DOTEA_P3 7318 213.0 NaN 7304.0 208.0 4063.0
DOTEA_P4 4817 213.0 31787.0 7304.0 208.0 4050.0
DOTEA_P5 5342 213.0 31787.0 NaN 45.0 NaN
DOTEA_P6 6181 NaN 31787.0 7304.0 NaN 4064.0
DOTEA_P7 4163 213.0 NaN 7304.0 45.0 4071.0
DOTEA_P8 6860 213.0 31787.0 7304.0 45.0 4064.0
INFO:root:Loading pre-defined network structure...
INFO:root:Model1 updated successfully with weights from model2 (left-aligned strategy).
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | net | VAE | 25.5 M | train
1 | dsc | Discriminator | 53.1 K | train
-----------------------------------------------
25.6 M Trainable params
0 Non-trainable params
25.6 M Total params
102.233 Total estimated model params size (MB)
666 Modules in train mode
0 Modules in eval mode
INFO:root:Total number of samples: 53356 from 8 datasets.
INFO:root:DataLoader created with batch size 256 and 64 workers.
INFO:root:Checkpoint successfully saved to "./DOTAE_P8/model_epoch500_20260411-161143.pt".
INFO:root:Checkpoint successfully saved to "./DOTAE_P8/model_epoch1000_20260411-171546.pt".
`Trainer.fit` stopped: `max_epochs=1000` reached.
INFO:root:Checkpoint successfully saved to "./DOTAE_P8/model_epoch1000_20260411-171547.pt".
INFO:root:Predicting using device: cuda
INFO:root:Predicting ...
INFO:root:Processing batch DOTEA_P1: ['adt', 'atac']
100%|██████████| 38/38 [00:06<00:00, 6.13it/s]
INFO:root:Processing batch DOTEA_P2: ['atac', 'rna']
100%|██████████| 36/36 [00:06<00:00, 5.83it/s]
INFO:root:Processing batch DOTEA_P3: ['adt', 'rna']
100%|██████████| 29/29 [00:05<00:00, 5.05it/s]
INFO:root:Processing batch DOTEA_P4: ['adt', 'atac', 'rna']
100%|██████████| 19/19 [00:06<00:00, 3.14it/s]
INFO:root:Processing batch DOTEA_P5: ['adt', 'atac']
100%|██████████| 21/21 [00:05<00:00, 3.58it/s]
INFO:root:Processing batch DOTEA_P6: ['atac', 'rna']
100%|██████████| 25/25 [00:06<00:00, 4.13it/s]
INFO:root:Processing batch DOTEA_P7: ['adt', 'rna']
100%|██████████| 17/17 [00:05<00:00, 3.08it/s]
INFO:root:Processing batch DOTEA_P8: ['adt', 'atac', 'rna']
100%|██████████| 27/27 [00:06<00:00, 4.33it/s]
... storing 'batch' as categorical
... storing 'label' as categorical
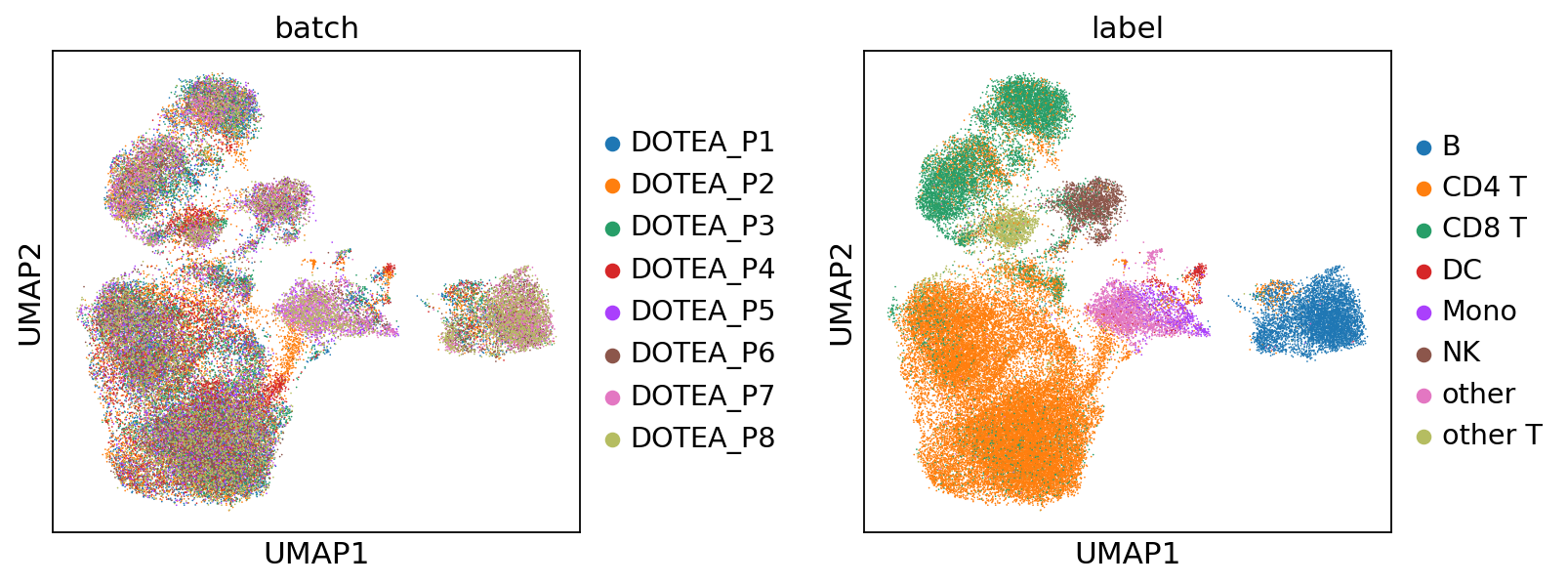
Step 5: Packaging for Future Use#
After integrating all batches, we can “pack” the unified dataset. This creates a reference that can be loaded directly in future sessions, skipping the incremental training steps.
5.1 Pack the Data#
[5]:
# Save the unified dataset to a new directory
model.pack_data(os.path.join(DATA_PATH, 'data', 'DOTEA_miracle'))
print(f"Data successfully packed to {os.path.join(DATA_PATH, 'data','DOTEA_miracle')}")
INFO:root:Processing batch 0: ['adt', 'atac']
100%|██████████| 38/38 [00:05<00:00, 6.57it/s]
INFO:root:Saving concatenated data for batch 0...
INFO:root:Processing batch 1: ['atac', 'rna']
100%|██████████| 36/36 [00:05<00:00, 6.21it/s]
INFO:root:Saving concatenated data for batch 1...
INFO:root:Processing batch 2: ['adt', 'rna']
100%|██████████| 29/29 [00:05<00:00, 4.88it/s]
INFO:root:Saving concatenated data for batch 2...
INFO:root:Processing batch 3: ['adt', 'atac', 'rna']
100%|██████████| 19/19 [00:05<00:00, 3.24it/s]
INFO:root:Saving concatenated data for batch 3...
INFO:root:Processing batch 4: ['adt', 'atac']
100%|██████████| 21/21 [00:05<00:00, 3.56it/s]
INFO:root:Saving concatenated data for batch 4...
INFO:root:Processing batch 5: ['atac', 'rna']
100%|██████████| 25/25 [00:05<00:00, 4.23it/s]
INFO:root:Saving concatenated data for batch 5...
INFO:root:Processing batch 6: ['adt', 'rna']
100%|██████████| 17/17 [00:06<00:00, 2.81it/s]
INFO:root:Saving concatenated data for batch 6...
INFO:root:Processing batch 7: ['adt', 'atac', 'rna']
100%|██████████| 27/27 [00:06<00:00, 4.36it/s]
INFO:root:Saving concatenated data for batch 7...
Data successfully packed to ./dataset/DOTEA_mtx/data/DOTEA_miracle
5.2 (Optional) How to Reuse Packed Data#
The following code snippet demonstrates how to load this packed dataset in a new Python session.
[6]:
# --- Example Usage in a New Session ---
# MIDAS.reset()
# configs = load_config()
# configs['num_workers'] = NUM_WORKERS
# # 1. Initialize directly from the packed directory
# model = MIDAS.configure_data_from_dir(
# configs=configs,
# dir_path=os.path.join(DATA_PATH, 'data', 'DOTEA_miracle'),
# save_model_path='your_path_to_save_model',
# format='mtx',
# transform={'atac': 'binarize'}
# )
# # 2. Load the weights from the final checkpoint of Stage 2
# model.load_checkpoint('your_path_of_checkpoint')
# # 3. Ready for further analysis or adding Batch 9...
# miracle = MIDAS.configure_new_data_from_dir(
# configs=configs,
# dir_path='your_path_of_new_data',
# # ... parameters ...
# )